Merkmalsintegrationstheorie
Die Merkmalsintegrationstheorie (im Original Feature Integration Theory) von Anne Treisman (1963) ist eine Theorie, die die menschliche Objekterkennung mithilfe visueller Aufmerksamkeit erklärt.
Den Ausgangspunkt für Treismans Ansichten stellt die Filtertheorie der Aufmerksamkeit von Donald Broadbent aus dem Jahr 1958 dar, welche besagt, dass es im Gehirn einen sogenannten „Filter“ gibt, der schon sehr früh Reize aufgrund physikalischer Merkmale selektiert (early selection, im Gegensatz dazu siehe für ein besseres Verständnis auch: Theorie der späten Selektion von Deutsch & Deutsch, 1963[1]) Da beide (Treisman – Deutsch&Deutsch-Kontroverse) keine eindeutige Antwort geben konnten, folgte 1995 eine Alternative von Lavie: nicht der Selektionsort (früh/spät), sondern die Anforderung an die Targetsituation determiniert die Interferenzen[2].
Einteilung in Stufen
[Bearbeiten | Quelltext bearbeiten]Präattentive Verarbeitung
[Bearbeiten | Quelltext bearbeiten]
Die Merkmale des noch nicht erkannten Objektes stehen zuerst frei und einfach nebeneinander (float free). Dieser Vorgang wird als Stufe der präattentiven Verarbeitung bezeichnet und läuft schnell, automatisch und unbewusst ab. Ähnliche Merkmale (z. B. blau) bilden Dimensionen (z. B. Farbe). Die Dimensionen sind jeweils abhängig von Detektoren, die für die entsprechenden Merkmale empfindlich sind. Ähnliche Detektoren sind wiederum in Merkmalskarten organisiert. Für jede Dimension gibt es somit eine eigene Merkmalskarte. Ein bestimmter Ort auf diesen Karten entspricht einem bestimmten Ort im visuellen Feld (Retina), der auf Reize anspricht, die auf diesen Bereich der Netzhaut fallen.
Attentive Verarbeitung
[Bearbeiten | Quelltext bearbeiten]Diese übereinstimmenden Orte verschiedener Karten werden durch gerichtete Aufmerksamkeit in einer nächsten Stufe der attentiven Verarbeitung einander zugeordnet, denn hier werden die Merkmale zu einem Objekt zusammengesetzt, was insgesamt eine Bottom-Up-Verarbeitung (siehe Top-down und Bottom-up) darstellt. Über eine zentrale Ortskarte werden die Ausgangssignale der Detektoren aller Merkmalskarten an jeweils dem einen Ort verfügbar, an dem sich zu dem Zeitpunkt der Fokus der Aufmerksamkeit befindet. Dadurch werden die Merkmale miteinander verknüpft. Durch die erforderliche gerichtete Aufmerksamkeit dauert dieser Prozess länger als die präattentive Verarbeitung. Den Fokus der Aufmerksamkeit vergleicht Treisman mit einer Art Lichtkegel (spotlight): befindet sich das Objekt innerhalb des „Lichtes“, kann es als einheitliches Ganzes wahrgenommen werden.
Vier Paradigmen
[Bearbeiten | Quelltext bearbeiten]Treisman benutzte vier experimentelle Paradigmen, die diese Stufentheorie stützen sollen. So können z. B. unterschiedliche Reaktionszeiten Hinweise auf entweder präattentive (kurze Reaktionszeit) oder attentive (lange Reaktionszeit) Verarbeitung geben.
Die Paradigmen lauten:
- Visuelle Suche
- Illusorische Konjunktionen (Verbindungen)
- Texturbereichstrennung
- Identifizierung und Lokalisation
Die visuelle Suche ist hierbei am bedeutendsten.
Visuelle Suche
[Bearbeiten | Quelltext bearbeiten]

Die visuelle Suche nach einem möglichen Zielreiz (Target) findet in einem Suchdisplay statt, welches eine variable Anzahl von Ablenkern (Distraktoren) enthält. Die Gesamtzahl der dargebotenen Zielreize und Ablenker wird als Displaygröße bezeichnet. Von der Versuchsperson ist zu entscheiden, ob sich neben den Ablenkern auch ein Zielreiz auf dem Display befindet. Die Merkmale der Ablenker können sich in nur einer Dimension wie etwa Farbe, Form, Bewegung usw. von den Merkmalen des Zielreizes unterscheiden (single feature search) oder in einer Verknüpfung (Konjunktion) von mehreren Merkmalsdimensionen (feature conjunction search).
Die parallele Suche erfolgt präattentiv (ohne Aufmerksamkeit), da sich der Zielreiz in seinem Merkmal von denen der Ablenker abhebt und sofort ins Auge springt (Pop-Out-Effekt). Dies ist nur möglich, wenn es nur ein variierendes Merkmal gibt (single feature search). Die Displaygröße hat dabei keinen Einfluss auf die Reaktionszeit. Der Pop-out-Effekt kann von evolutionären Prozessen überlagert werden: Ein wütendes Gesicht in einer Menge fröhlicher Gesichter springt heraus; ein fröhliches Gesicht in einer Menge wütender Gesichter jedoch nicht.[3]
Wird das Display nach einem Zielreiz abgesucht, der sich aus verschiedenen Merkmalen der Ablenker zusammensetzt (feature conjunction search), spricht man von einer seriellen Suche. Gerichtete Aufmerksamkeit ist erforderlich, denn der Proband muss das ganze Display „abscannen“, um besagten Zielreiz zu entdecken. Die Suchrate beträgt mehr als 10 ms pro Item, wobei die Reaktionszeit von der Displaygröße abhängig ist (je größer das Display, desto länger die Reaktionszeit).
Abhängig davon, ob im Display ein Zielreiz vorhanden ist oder nicht, wird bei der seriellen Suche zwischen der selbst-abbrechenden Suche (self-terminating search) und der erschöpfenden Suche (exhaustive search) unterschieden. Bei der selbst-abbrechenden Suche wird das Display nur solange abgesucht, bis der Zielreiz gefunden wurde, was natürlich nur möglich ist, wenn er auch überhaupt vorhanden ist. Dies geschieht im Durchschnitt, nachdem die Hälfte der Items abgesucht wurde. Bei der erschöpfenden Suche werden alle Display-Items abgesucht, bevor festgestellt werden kann, dass kein Zielreiz vorhanden ist. Demzufolge beträgt das Verhältnis zwischen der Dauer einer erschöpfenden und der durchschnittlichen Dauer einer selbst-abbrechenden Suche 2:1.

Texturbereichstrennung
[Bearbeiten | Quelltext bearbeiten]
Die Texturbereichstrennung ist ein paralleler Prozess, der keine Aufmerksamkeit erfordert. Dafür eignen sich nur Targets, die sich in einem Merkmal unterscheiden, d. h. nur Features und keine Konjunktionen.
Illusorische Konjunktionen
[Bearbeiten | Quelltext bearbeiten]
Auf der zweiten Stufe der Merkmalsintegrationstheorie werden wie bereits erwähnt die Merkmale von der ersten Stufe mithilfe gerichteter Aufmerksamkeit zu einem kohärenten Objekt zusammengefügt. Wenn jedoch die Aufmerksamkeit nicht auf den bestimmten Ort, wo sich das Objekt befindet, fokussiert ist, besteht die Gefahr, dass die Merkmale falsch miteinander verknüpft werden und somit eine illusorische Konjunktion entsteht.
Identifizierung und Lokalisation
[Bearbeiten | Quelltext bearbeiten]Unterscheidet sich das Target in nur einem Merkmal von den Distraktoren, kann man dieses identifizieren, ohne genau zu wissen, an welcher Stelle es sich auf dem Display befindet. D.h. bei der Merkmalsbedingung funktionieren Identifizierung und Lokalisation unabhängig voneinander. Bei der Verknüpfungsbedingung muss das Target allerdings mithilfe gerichteter Aufmerksamkeit (also auf der zweiten Stufe) lokalisiert werden. Erst anschließend ist seine Identifizierung möglich.
-
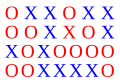 Verknüpfungsbedingung: Konzentration auf 2 Merkmale (Farbe rot und Form X), um den Zielreiz zu finden.
Verknüpfungsbedingung: Konzentration auf 2 Merkmale (Farbe rot und Form X), um den Zielreiz zu finden. -
 Merkmalsbedingung: Konzentration auf 1 Merkmal (Farbe gelb), um den Zielreiz zu finden.
Merkmalsbedingung: Konzentration auf 1 Merkmal (Farbe gelb), um den Zielreiz zu finden.

Literatur
[Bearbeiten | Quelltext bearbeiten]- Deutsch, J. & Deutsch, D. (1963). Attention: Some theoretical considerations. Psychological Review, 70:80–90.
- Goldstein, B. E. (2002). Wahrnehmungspsychologie. Heidelberg: Spektrum Akademischer Verlag.
- Müsseler, J. & Prinz, W. (2002). Allgemeine Psychologie. Heidelberg: Spektrum Akademischer Verlag.
- Treisman, A. M. & Gelade, G.(1980). A Feature-Integration Theory of Attention. Cognitive Psychology, 12, 97–136. (PDF)
Weblinks
[Bearbeiten | Quelltext bearbeiten]Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ J. A. Deutsch, D. Deutsch: Attention: Some theoretical considerations. In: Psychological Review. Band 70, Nr. 1, Januar 1963, ISSN 1939-1471, S. 80–90, doi:10.1037/h0039515 (apa.org [abgerufen am 19. Juni 2022]).
- ↑ Nilli Lavie: Perceptual load as a necessary condition for selective attention. In: Journal of Experimental Psychology: Human Perception and Performance. Band 21, Nr. 3, 1995, ISSN 1939-1277, S. 451–468, doi:10.1037/0096-1523.21.3.451 (apa.org [abgerufen am 19. Juni 2022]).
- ↑ Christine und Ranald Hansen (1988): Finding the Face in the Crowd: An Anger Superiority Effect. Journal of Personality and Social Psychology, 54, S. 917–924